葫芦客
葫芦客
介绍
微服务架构中,服务之间的调用关系非常复杂,一个服务可能组合调用不同的微服务,调用过程中可能因为某个网络延迟高、出现异常错误等导致请求失败,为了方便快速排错和监控,需要一套服务追踪来进行管理。Spring Cloud Sleuth 提供了分布式服务链路监控的解决方案,我最近搭建此方案对项目进行了实践,带着对链路监控数据流及采集上报性能有担忧风风险,对框架深入进行了研究
基本说明
术语
详细参考:https://zipkin.io/pages/instrumenting.html
详细参考:https://github.com/openzipkin/zipkin-api/blob/master/thrift/zipkinCore.thrift
- Span 基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
- Trace 一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace
- Annotation 用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
网络时间计算
- sr-cs:网络延迟
- ss-sr:逻辑处理时间
- cr-cs:整个流程时间
zipkin-ui Annotations说明
- Client Start 对应 Client Sent
- Server Start 对应 Server Received
- Client Finish 对应 Client Received
- Server Finish 对应 Server Finish
span下所有annotation的Relative Time为相对整个trance的开始时间,所以可以用这个相对时间来计算每个事件的间隔耗时
日志采样
合理配置采样规则能减少系统开销,同时在开发人员跟踪时调试可以增加强制采样header参数:X-B3-Flags设置为1 或 X-B3-Sampled设置为1
原理说明
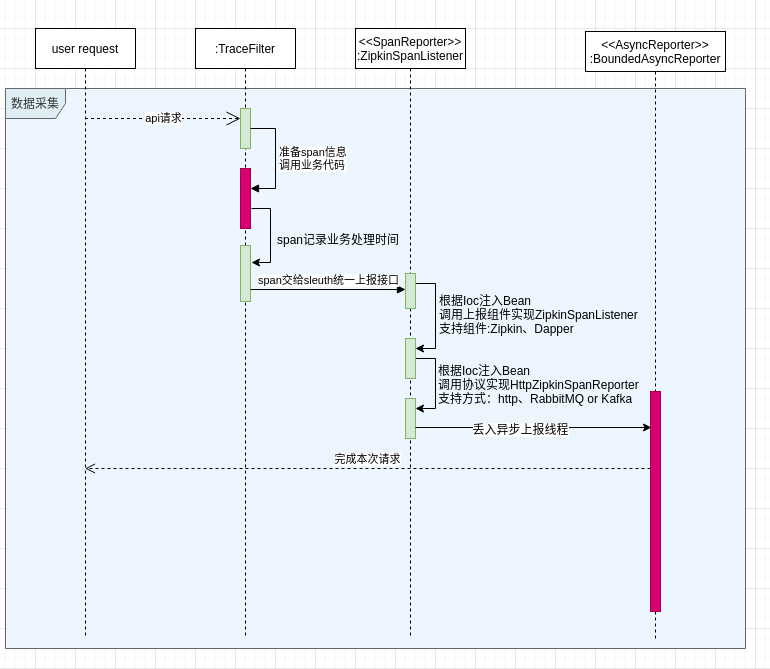
花了一整天时间深入研究源码后,画了以下两个图记录下原理,觉得这个方案值得学习,对于以后工作中处理程序异步线程间队列缓冲数据交换时可以借鉴
-
采集上报原理简析

-
数据采集时序图
配置使用
- 监控采集端pom依赖
<!--服务链路监控 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>-
监控采集端参数配置
spring: zipkin: #采集开关,线上请暂时关闭(请提入git配置文件中) enabled: true #日志中心地址(请提入git配置文件中) base-url: http://service-zipkin sleuth: sampler: #设置抽样采集为100%,默认为0.1,即10% percentage: 1.0 -
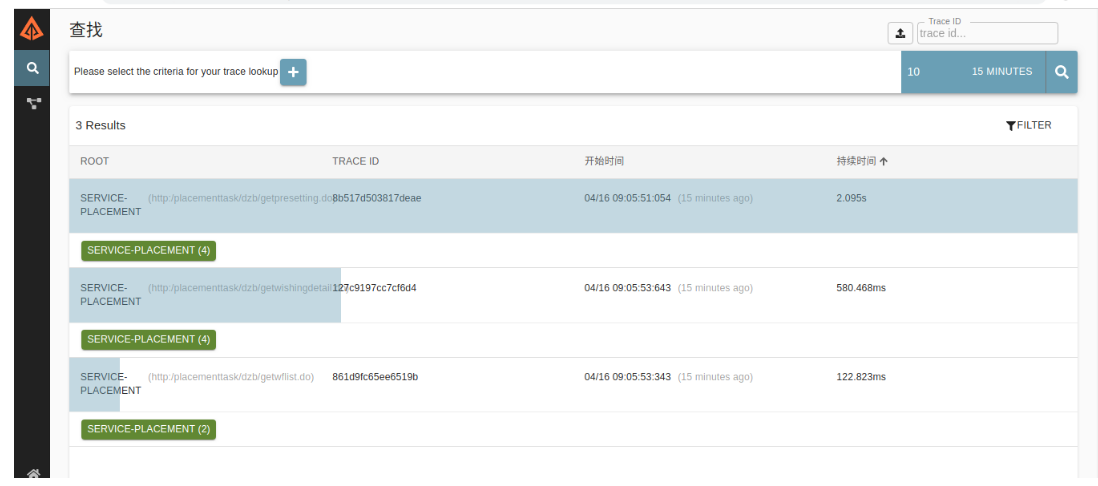
链路监控查询